All Tutorials
Learn NVIDIA Holoscan through hands-on tutorials covering fundamental concepts, advanced techniques, and best practices. These step-by-step guides help you understand how to build sensor processing pipelines, integrate AI models, optimize performance, and deploy applications. Whether you're new to Holoscan or looking to expand your expertise, these tutorials provide practical knowledge for developing real-time streaming applications.
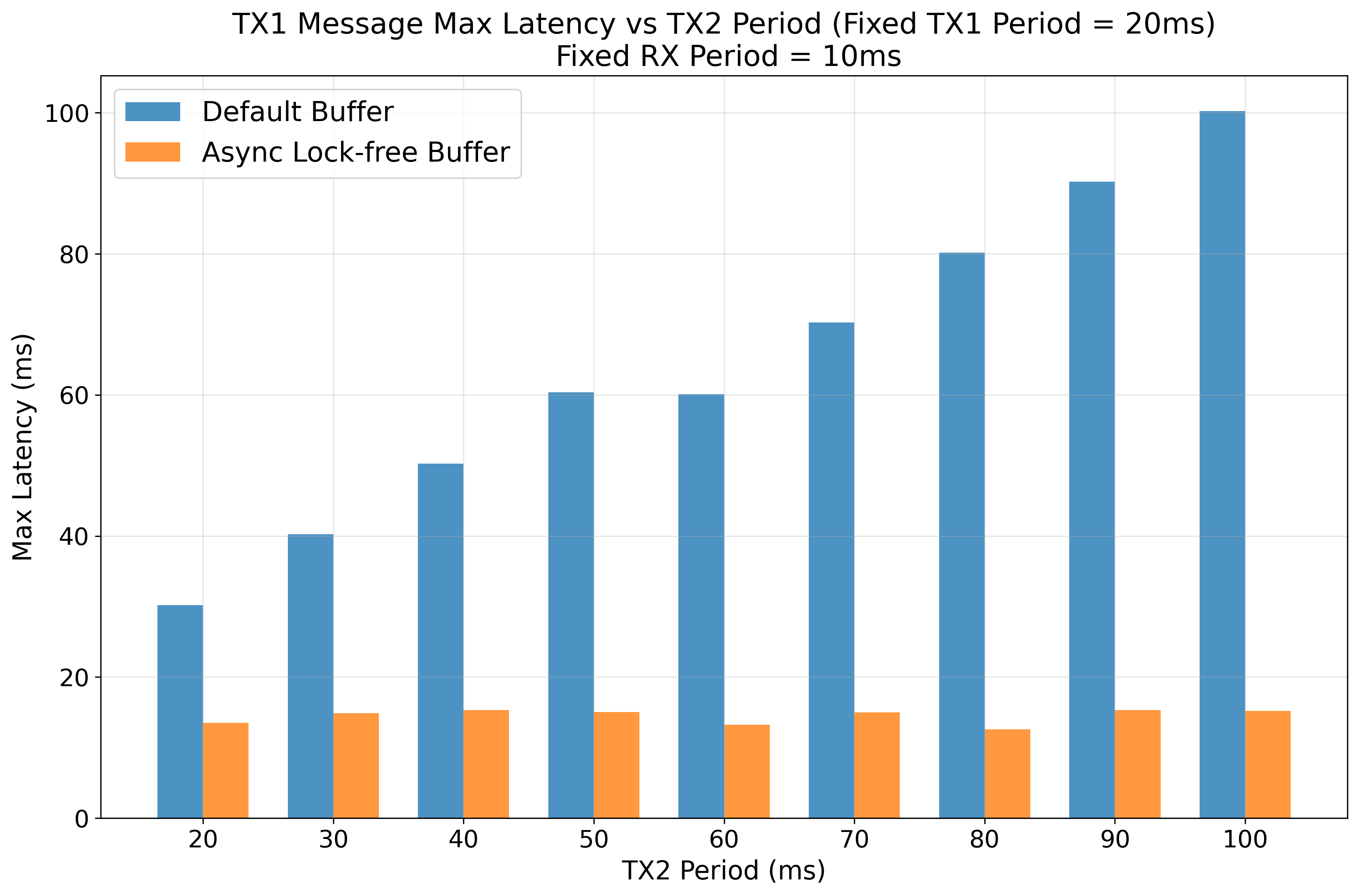
Asynchronous Lock-free Buffer
This tutorial demonstrates the impact of using an asynchronous lock-free buffer with SCHED_DEADLINE scheduling policy in Linux on the message latency.

NVIDIA CloudXR Runtime for XR Applications
N/AIn this tutorial, we will walk through the process of setting up the NVIDIA CloudXR OpenXR Runtime for XR Applications.

Using holohub operators in external applications
C++In this tutorial, we will walk through the process of using holohub operators in external applications.
Holoscan SDK Response Time Analysis
A tutorial demonstrating how to analyze and optimize real-time performance in Holoscan applications
High Performance Networking with Holoscan
C++How to use the Advanced Network library (ANO) for low latency and high throughput communication through NVIDIA SmartNICs.
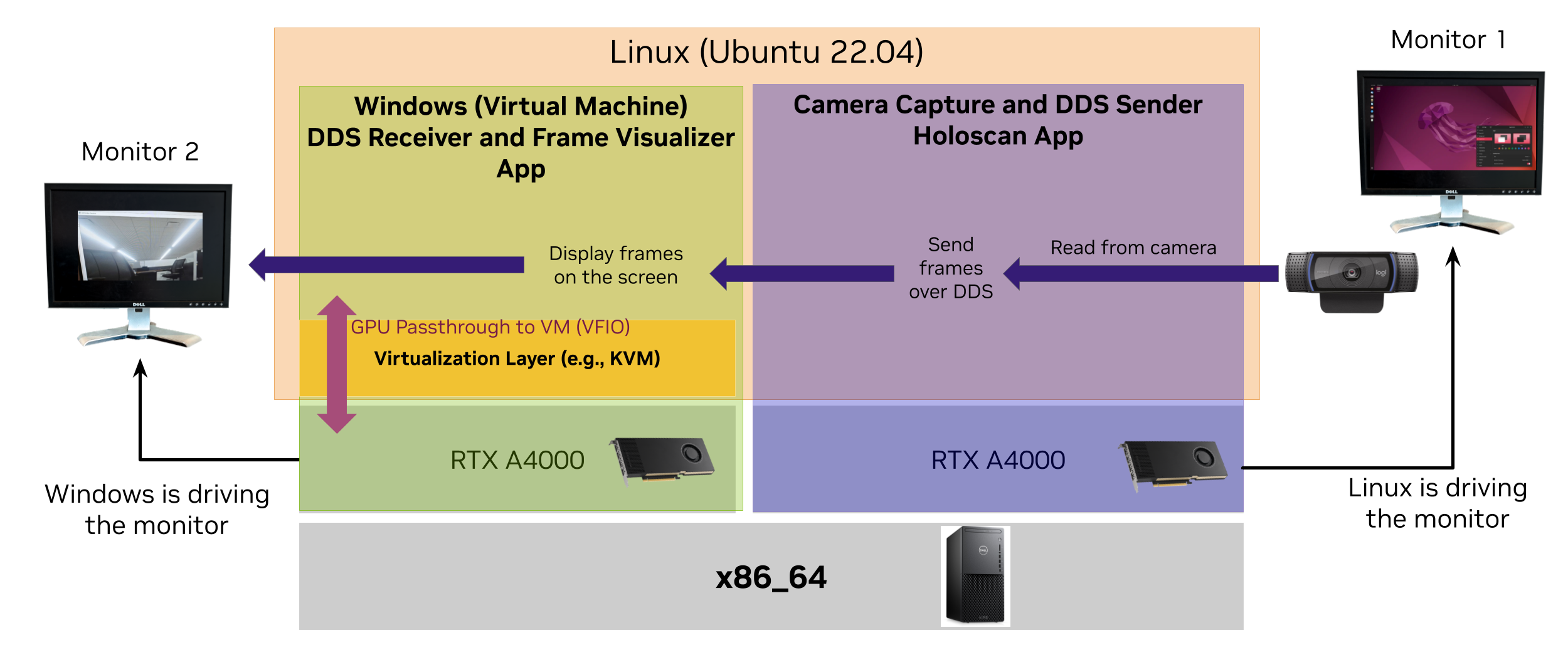
Holoscan & Windows Application
bashDemonstrates interoperability between a Holoscan on Linux and a Windows VM application on a single machine
NVIDIA Holoscan Bootcamp lab materials
PythonHoloscan Bootcamp Jupyter notebook for self-paced learning of Holoscan core concepts
GPU Direct Storage on IGX
PythonModern-day edge accelerated computing solutions constantly push the boundaries of what is possible.
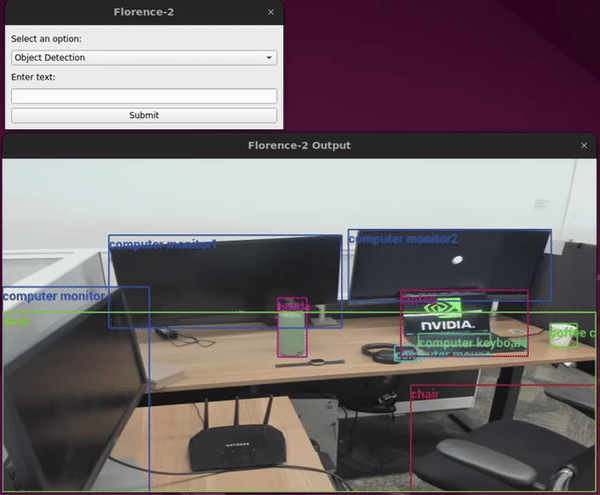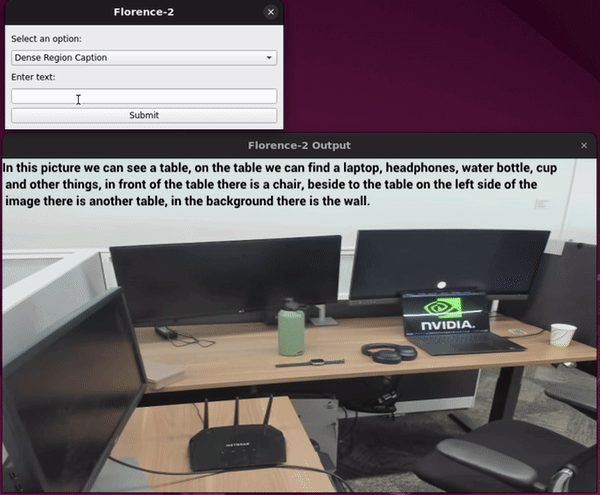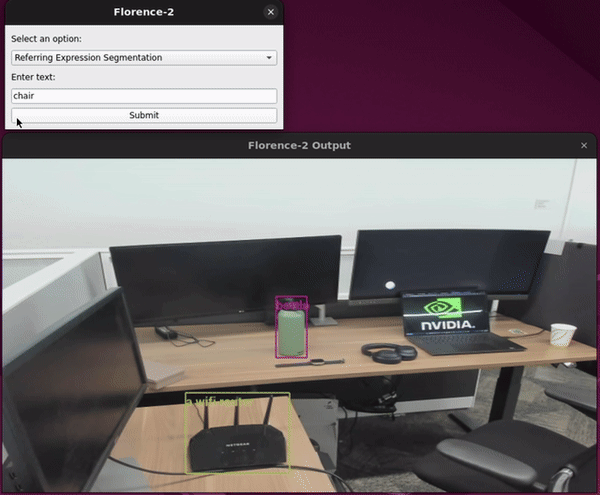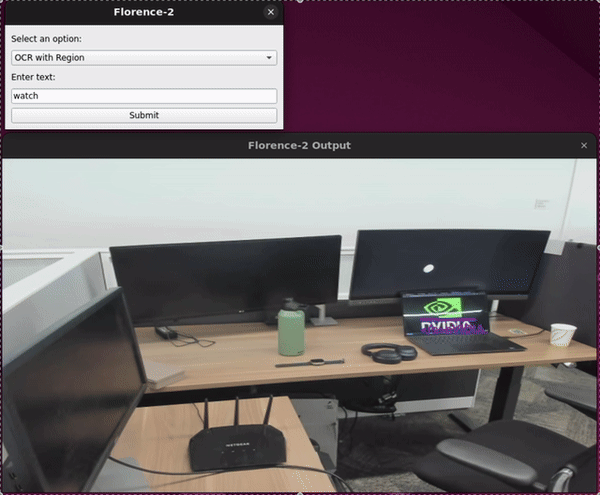
Adding a GUI to Holoscan Python Applications
PythonIn this tutorial, we will walk through the process in two scenarios of creating a multi node application from existing applications.
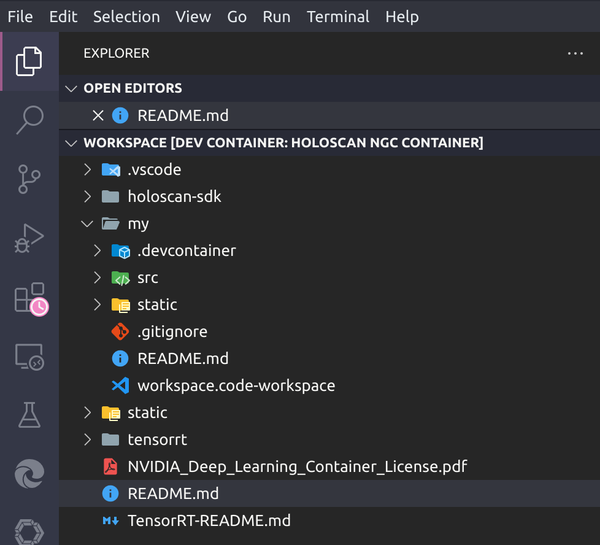
VSCode Dev Container for Holoscan
Dev Container template with VS Code launch profiles to debug applications based on the Holoscan SDK NGC Container.
Interactively Debugging a Holoscan Application
C++Demonstrates how to debug a Holoscan application with common software tools.
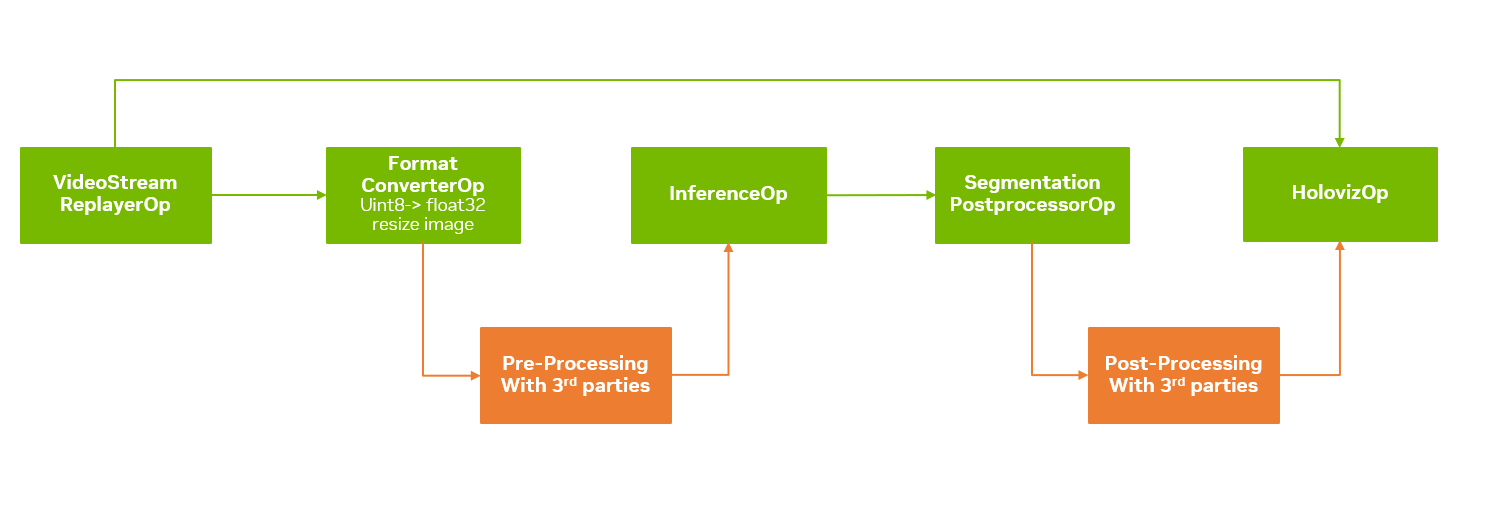
Integrate External Libraries into a Holoscan Pipeline
PythonGeneral tutorial on how to integrate external libraries into Holoscan SDK based applications and pipelines
Self-Supervised Learning for Surgical videos
PythonThe focus of this repo is to walkthrough the process of doing Self-Supervised Learning using Contrastive Pre-training on Surgical Video data.
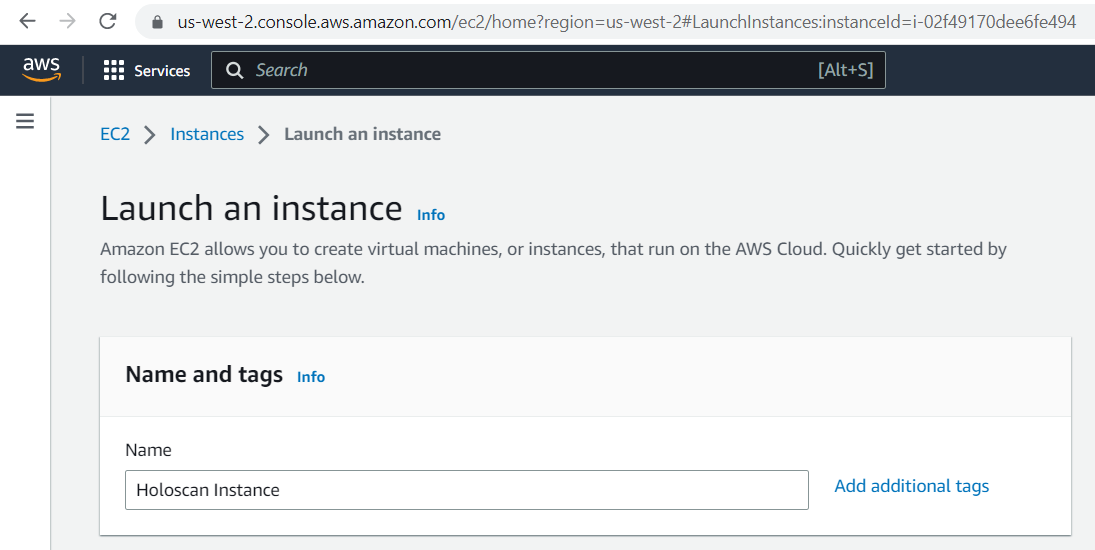
Holoscan Playground on AWS
The Holoscan on AWS EC2 experience is an easy way for having a first try at the Holoscan SDK.
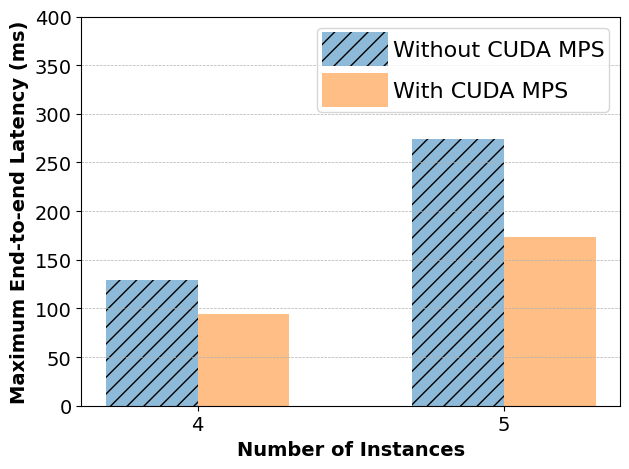
CUDA MPS Tutorial
This tutorial describes the steps to enable CUDA MPS and demonstrate few performance benefits of using it.
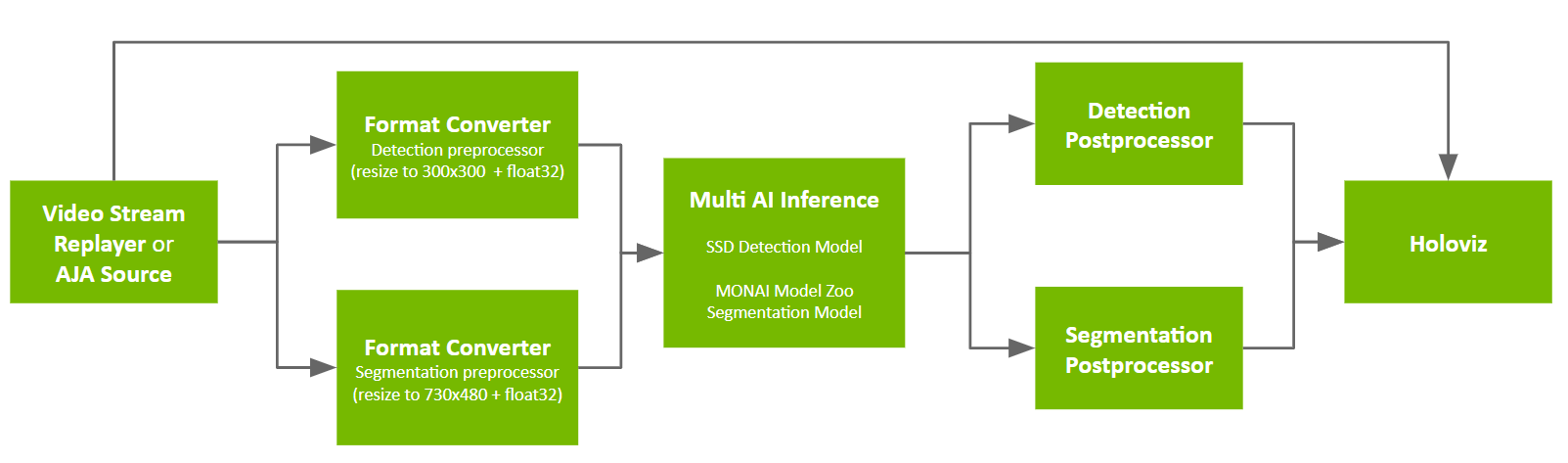
Creating Multi-Node Holoscan Applications
PythonIn this tutorial, we will walk through the process in two scenarios of creating a multi node application from existing applications.

Deploying Llama-2 70b model on the edge
PythonThis tutorial will walk you through how to run a quantized version of Meta's Llama-2 70b model as the backend LLM for a Gradio chatbot app, all running on an NVIDIA IGX Orin.

DICOM to OpenUSD mesh segmentation
PythonIn this tutorial we demonstrate a method leveraging a combined MONAI Deploy and Holoscan pipeline to process DICOM input data and write a resulting mesh to disk in the OpenUSD file format.